User
Two friends meet after a long time and greet each other like [source motion]. What if one of the friends becomes overly touched upon meeting the other friend?
Recent advancements in large language models (LLMs) have significantly improved their ability to generate natural and contextually relevant text, enabling more human-like AI interactions. However, generating and understanding interactive human-like motion, where multiple individuals engage in coordinated movements, remains challenging due to the complexity of modeling these interactions. Additionally, a unified and versatile model is needed to handle diverse interactive scenarios, such as chat systems that dynamically adapt to user instructions and assigned roles. To address these challenges, we introduce MoLaM, the Interactive Motion-language model, which integrates both language and motion modalities to effectively understand, generate, and control interactive motions in multi-turn conversational contexts. Unlike previous studies that primarily focus on uni-directional tasks such as text-to-motion or motion-to-text, MoLaM employs a unified architecture capable of simultaneously understanding and generating both motion and text modalities. Given the absence of an appropriate dataset to support this task, we introduce Inter-MT2, a large-scale instruction-tuning dataset containing 82.7K multi-turn interactive motion instructions, covering 153K interactive motion samples. Inter-MT2 spans diverse instructional scenarios, including motion editing, question answering, and story generation, leveraging off-the-shelf large language models and motion diffusion models to construct a broad set of interactive motion instructions. We extensively evaluate the versatility of MoLaM across multiple interactive motion-related tasks, including motion-to-text, text-to-motion, reaction generation, motion editing, and reasoning about motion sequences. Notably, MoLaM is the first model capable of effectively addressing all these tasks within a single unified framework, achieving competitive performance compared to task-specific methods.
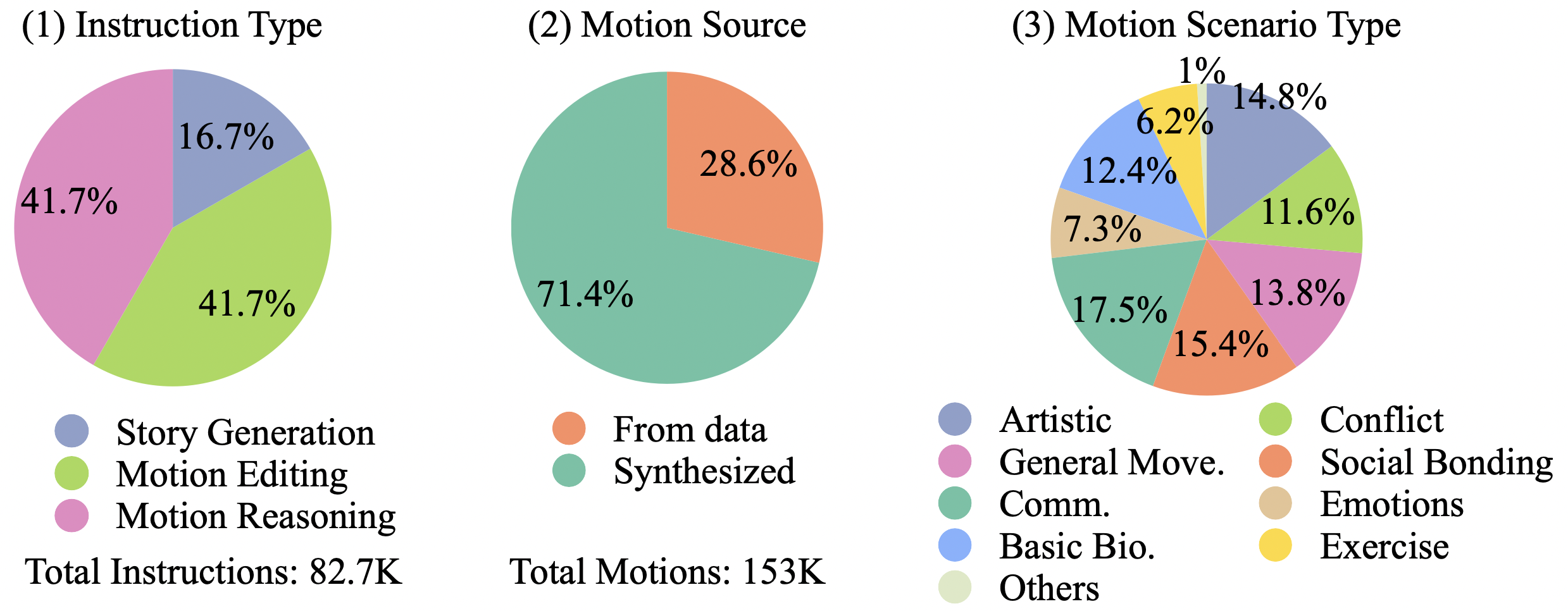
Current datasets (Inter-X, InterHuman) for modeling interactive motions lack sufficient diversity in instructions and do not include multi-turn conversations. To address this gap, we introduce INTER-MT2: INTERactive MUTI-Turn Motion-Text dataset. This dataset covers a variety of interactive motion scenarios with multi-turn conversations, diverse instructions, and spatiotemporally aligned motions between two individuals.
Our pipeline creates samples in two ways. First, starting with a dataset motion, we generate a caption and instruction and then use InterGEN to synthesize a matching motion, yielding both the original and synthesized motions with the instruction. Alternatively, we generate two captions and instructions to synthesize two motions, producing samples entirely from synthesized motions. This method blends data-sourced and generative motions for reliable interactive motion modeling.
Overall, we collected 82K multi-turn conversations, including 96K synthesized and 56K real motions. Figure 2 shows statistics and samples from our Inter-MT2, where motion scenarios are classified using a large language model with motion captions. We aim to showcase spatiotemporally aligned motions between two individuals, summarizing everything on the project page.
We pursue the versatility of MoLaM through a unified architecture that can simultaneously input and output both motion and text modalities. Based on the pre-trained LLMs, our training process can be divided into three stages:
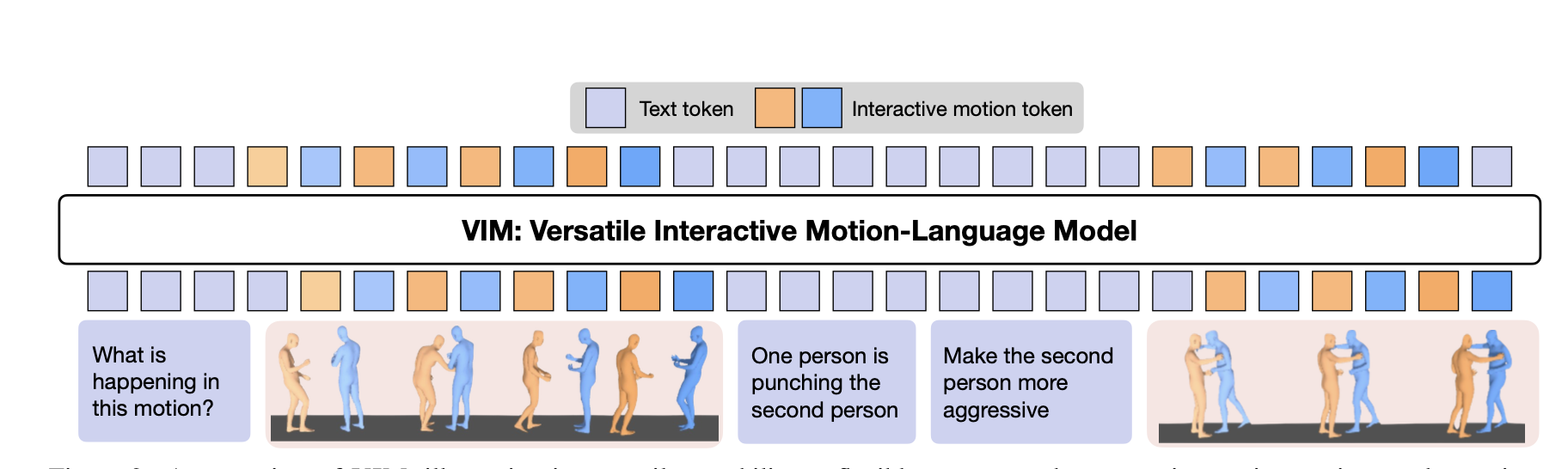
Two friends meet after a long time and greet each other like [source motion]. What if one of the friends becomes overly touched upon meeting the other friend?
Let's have a scene where two people are interacting, like the motion you see in [source motion]. What if the person who is walking up is a bit more respectful?
Two individuals are performing a self-defense technique, where one person strikes with the left hand, and the other intercepts the attack. It's similar to [source motion]. The first person seems too aggressive. Can you make the second person counter in a more forceful and confident way?
Two friends are meeting up like in [source motion]. The first person seems way too aggressive. Can you make this person more gentle?
One person pats the other on the back, and the other person turns to look.
The first person holds onto the second's right forearm, then stumbles and drags them down.
One person approaches and massages the other's shoulders using both hands.
One person steps forward and steps on the left foot of the other person.
Two people sit facing each other, taking turns to play rock-paper-scissors by waving their right arms to the right three times each.
Two people face each other and raise both hands in front of their heads. Then, they move forward and clap.
The initial individual is seated on the chair. The subsequent individual approaches from the left of the first person, grasps his/her left arm with both hands, and assists him/her in rising.
Two people walk towards each other, and when they meet, their arms collide.
@article{park2024versatile,
title={A Unified Framework for Motion Reasoning and Generation in Human Interaction},
author={Park, Jeongeun and Choi, Sungjoon and Yun, Sangdoo},
journal={arXiv preprint arXiv:2410.05628},
year={2024}
}